Acoustic Learning,
Inc.
Absolute Pitch research, ear training and more
Albert Bregman's Auditory Scene Analysis begins by asking: how do we recognize an "object"?
It seems that we lump together characteristics and call that lump an object. (If it's an auditory object, which occurs over time, we can call it a stream.) Multiple characteristics form an object, and belonging to that object is what groups them together.
However, objects do not share characteristics. Any one characteristic can belong to only one object. This is the principle of exclusive allocation, well illustrated by the famous faces-or-vase illusion. You cannot see both vase and faces at the same time, because there is only one definitive characteristic available-- the contour-- and it stubbornly refuses to belong to more than one object. When the contour is "captured" by the faces, the vase is lost. When the vase reclaims the contour, the faces disappear.
Also, a characteristic must belong to some object. You might not have realized you also can't avoid seeing at least one image. There is no such thing as a disembodied characteristic. The only way to see this picture differently is to mentally assign the contour to a different object, even if that object is abstract (e.g. "a blob" or "a couple of lines")-- but no matter what, if you pay attention to the image you cannot prevent yourself from seeing some object. When we perceive a characteristic, it will be assigned to an object, and only that object, whether we like it or not.
This might make sense of how a person can perceive a phoneme without realizing it. An illiterate person will recognize the difference between bog and dog because they do hear the difference between b and d-- but they are not aware of the distinction they've made. This could be because, even though they physically heard the separate phonemic qualities of b and d, and made their unconscious decision based on that difference alone, they consciously group the phonemic qualities together with the rest of the word. They have no concept of a "phoneme" object to which they could otherwise assign those same characteristics, so the phonemic characteristics-- even if clearly perceived-- get absorbed into the word-object instead. The phoneme has no separate identity; it is recognized, but as a mere characteristic of its word.
Maybe this is why people can produce music with perfect accuracy without knowing what intervals or pitches they're making. For them, the sensations "belong" to the melody. The characteristics of each tone are assigned to the melody, and captured by it, and thus made inaccessible for recognizing the individual pitches. They couldn't tell you what sounds they're making for the same reason that a naive listener can distinguish between a major and a minor chord, and hear the single pitch change, but not know which pitch has changed-- because the pitch "belongs" to the chord. And besides, a "pitch" judgment can be affected by duration, timbre, rhythmic function, intensity, or any number of characteristics; without better information, these are assigned to the tone-object and are evaluated together as its "pitch".
Perhaps this also explain linguistic "chunking". We can't simultaneously perceive syllables and phonemes, or chords and pitches, because, like the faces and vase, they use the same definitive characteristics as each other. We can hear either "a C-major triad", or "a major third and a minor third", or "C, E, and G". The principle of exclusive allocation mandates that the only way to "hear" more than one of these objects from the same sensory input is to re-visit the sense memory and reassign the shared characteristics-- which is exactly what I was describing as the decoding process. Therefore, our direct perception of music or language, when listening, depends on the objects we are capable of conceiving; our direct production of music or language, when reading, depends on the size of the chunks we are capable of apprehending.
Going back to basic objects, though: Auditory Scene Analysis says that characteristics are grouped by similarity and distance.
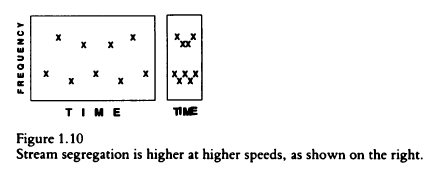
Bregman offers an illustration of how "distance" works with auditory grouping. High and low tones may appear to be alternating when played slowly, but if the time between tones is removed they will blend with each other to create two new and different objects (in this case, separate ascending and descending scales). Plotting the tones on a chart creates the effect spatially. On the left, there appears to be a single wide distribution of x's, but on the right there appear to be two discrete lines. The horizontal "distance" between them has been eliminated, so the tones become compressed into two lines.
From this chart, Bregman continues:
If the analogy to audition is a valid one, this suggests that the spatial dimension of distance in vision has two analogies in audition. One is separation in time, and the other is separation in frequency. Both, according to this analogy, are distances, and Gestalt principles that involve distance should be valid for them.
But the analogy to audition is not valid. If "distance" is an area of nothingness, then auditory distance must be time. Visual objects are bounded in space, and are separated by empty space; auditory streams are bounded in time, and are separated by empty time. Although it is tempting to be drawn in by the metaphor of notes described as "high" and "low", and thereby believe the difference between the mathematical values of vibratory cycles to be a "separation in frequency", this separation is not distance. It is a numerical metaphor, and a theoretical calculation-- not a perceptible physical absence of sensation. Pitch frequencies are, in truth, Bregman's stated second criterion for object grouping: similarity.
The overtone series alone demonstrates the fallacy of frequency as "distance". An overtone series may span the entire musical grand staff but, despite this wide "distance" of frequencies, still be perceived as one tone. If frequency were "distance" then hearing any complex tone would be improbable; the widely distant frequencies of its overtone series would always be perceived as separate tones. When any overtonal frequency is tuned into dissimilarity, it detaches itself into a separate tone, and when overtones are only somewhat dissimilar-- as with this tune in the Bohlen-Pierce scale-- you can hear how each tone struggles to cohere. Bregman's "Figure 1.10" is misleading; if his chart included the overtone series, the entire chart would become black with x's and instantly destroy the convenient visual analogy. Not only are overtone frequencies similar, but they occur simultaneously and therefore have no temporal distance between them. If overtonal frequencies do resist integration, it is because of their perceived dissimilarity, not "distance" from each other.
However it arose-- from the metaphor of "high" and "low" tones, from the fact that one frequency value can be subtracted from another, from the illusion of notes "moving up and down"-- the idea of a psychological "distance" between tones must be one of the most destructive concepts to have been wreaked on musicianship.
A musical frequency does not travel any "distance". A musical frequency does not "move" from one place to another. A moving object changes its speed, or changes its position, and consequently that object produces a different frequency. A physical object moves; its musical frequency changes. Musical frequencies do not describe the space through which an object moves; musical frequencies describe the velocity and the complexity of the movement itself. The illusion of musical motion is created by the presentation of different frequencies, from which we receive the distinct impression that something has moved-- and, having no visible object to which we may ascribe the motion, we mistakenly infer that the object in motion must be the musical note, and we imagine that the frequencies are "positions" to which the note has moved.
The fact that these pitch "positions" can indeed be shown as some distance apart on a musical score or a piano keyboard only reinforce the unfortunate fallacy. Because it is possible to measure this spatial "distance", Bregman and legions of musicians before and after him mistakenly think that there is a "distance" between tones. But a spatial gap between two visible objects exists as a vacuum; a temporal gap between two auditory streams exists as silence. The mathematical gap between two vibratory frequencies does not exist as anything. The supposed gap is a numerical difference, and a psychological difference, not the measurement of an empty space.
In essence, I've said this same thing here before. It certainly seems to be true, if apparently contradictory, that absolute pitch ability will be impossible to acquire until tones can be recognized without regard to their positions on the spectrum. But this time around, I've also realized that denying "distance" as a legitimate musical concept could imply the end of the "interval" as we know it.
The only time that "distance" between notes is at all meaningful is when the note is on the page-- and a note on a page indicates instrumental production, not perceptual quality. Instrumental fingering does exist in physical space. Perceptual similarity does not. A non-musician, unfamiliar with the conventions of musical notation, will confidently state that F and G are "nearer" to each other than F# and G. A musician who is not so fooled should nonetheless find it obvious that the "half step up" of E to F is palpably different from the "half step up" of F to F#... when in C-major.
Kodaly had it right-- the relative pitch of an "interval" is not defined by its distance from the previous note. The relative pitch of an interval is defined by its relative consonance versus a tonic. Notes do not "go to" each other as a melody "moves up and down"; rather, as each new note occurs, that note either compounds or relieves tension in the ongoing emotional communication. This provides yet another reason why a person can sing a perfect melody and have no concept of the intervals they're producing; the natural production of a melody does not start from scratch with every new tone. Sung tones are not "measured" directly from any of their neighbors, but flow around a tonic in an unconscious understanding of the melodic pattern of tension and release. This seems at once a convenient explanation for why the average unskilled singer finds it so easy to inadvertently transpose to a random key, and yet finds it extremely difficult to deliberately sing a dissonant note.
Perhaps you might protest that intervals do form a relationship with each other, regardless of the tonic. I disagree. I would say that intervals form a relationship with each other because of the tonic. As the most obvious example, think of vocalists whose harmonies are praised (Simon and Garfunkel, Indigo Girls, etc) or consider experience you might have trying to sing a harmony yourself. The praiseworthy goal is blending; becoming one. Where one voice produces a particular emotional tension relative to the current tonic, a second voice blended with the first creates a more complex tension. In other words, the purpose of an "interval" is not to create a relationship between two notes, but to communicate a more complex emotional message still relative to the overall tonality. By extension, chords or any other structures larger than intervals fulfill the same function-- of introducing still more complex patterns of tension and relaxation, or tension within relaxation, or relaxed tension, or whatever specific emotional expression requires more subtlety or sophistication than a single tonal percept. But an interval alone can make the point; imagine the effect of playing a single tritone (in whatever key) and compare its feeling to playing that same tritone with its neighboring fifth. To me, these two sounds could be distinguished as "concern" versus "anxious frustration". You would undoubtedly assign different words to these same tones, but you must agree that one communicates a more complex emotion than the other; and that message doesn't fundamentally change in transposition, because the emotional message is relative to the tonality, not inherent in the "interval" relationship. If you play the same pitches in a different tonality their emotional message is drastically altered, despite their unchanging intervals.
What then is to be made of the instrument-- voice, wind, or string-- that produces only one note at a time, and is called upon to produce a harmony? It must blend, yes, but isn't that blend directly dependent on the melodic line rather than the overall tonic? Here I'm asking practically. Conceptually, the issue is the same as I've already described, in that the combined harmony communicates a more sophisticated single concept relative to the tonic, but how does a musician produce only one of those notes? Isn't it necessary to sing "a third up" or "down" or whatever distance the harmony demands? Of course, most of us singers will remember that the most effective strategy is to rethink and relearn a harmony so that to us it becomes the melody, which automatically makes it relative to the tonic; but the most successful professional singers can produce any requested harmony instantly, on demand, on the fly. Their note must be relative to the melodic line, mustn't it? Well, yes, it must-- but I don't know of any singers who do this by singing "up" or "down". That's a half-truth; I don't know any singers who do this well by singing "up" or "down". The singers I've known who sing "up" or "down" describe having to force themselves to ignore the melody and the tonality so they don't get drawn away from the line they're attempting to sing. The singers I've known who can effortlessly vocalize harmonies are those who "feel" the notes, and who produce harmonies which complement the melody while still sounding good within the tonality. These singers produce an appropriate and effective harmony because they understand how their single note affects and contributes to the complete unified message.
But what happens when the message is not unified? This was posed to me recently. What happens when there's more than one message being spoken? A major difference between music and acting, I was told, is that in music we are often required to attend to "multiple lines", while in speech and speaking there is only one speaker at a time. Although it's questionable whether or not it's possible to pay attention to more than one thing at a time, it is flatly untrue that speech (and acting) is comprehensible only when there is one speaker. The difference lies in what is comprehended. Ten thousand people speaking together communicates an entirely different concept than a single orator; that is, you can recognize a stadium of football fans for what they are, and you can understand their opinion of the latest play, without knowing what any one of them is saying. When two or more people on your favorite talk show start to argue, you may not follow any one of their arguments, but you still know that they are arguing with each other (and not agreeing). In other words, when more than one person is speaking at the same time, you stop listening to their individual messages and start paying attention to their relationship-- and that relationship is defined by its context. If there is no context, you must force yourself to pay attention to only one speaker or you will receive only meaningless confusion.
Rather than stretch the analogy, I'll ask you to think of what you know of music. When two (or more) people are singing, or when two (or more) instruments are playing, do you really hear each of them independently? When it's performed well, do you really pay attention to what each of them, independently, is expressing? In music or language, I would argue that a message of "multiple lines"-- when well-performed-- communicates the relationship between the voices, within their (tonal) context. It is not intended to communicate multiple individual ideas.
Each tone has a relationship to its surrounding tones, yes. But to think of this relationship as an "interval" in the classic sense is to insist that the melodic line instantiates a brand-new tonic with each new note, to which every following note must be related before becoming a new tonic. Rather, each note combines with its neighbor to create patterns of tension and relaxation, of dissonance and consonance, which define their relationships to each other in service of the overall context. In this view, the classic interval ("major sixth up") tells you nothing about the musical "auditory scene". The classic "distance" interval can be noticed and extracted, but at the expense of every other relationship and the entire tonality besides. In this view of music, therefore, the classic interval cannot meaningfully exist.
In his second chapter, "Sequential Integration", Bregman unintentionally gives the phonemicists another slap in the face:
We should remember that even the simple sound "k" , when examined at a microscopic level, consists of three acoustically distinguishable parts, a brief silence when the closure occurs, a sharp burst of noise when the closure is released, and a longer "h" sound (aspiration) at the end. The "k" has no special claim to being a true acoustic unit. (p 68-9)
Is this, perhaps, the clearest answer of why an illiterate can unconsciously detect phonemic differences? Now that you know that a phoneme is not a single sound, but is actually a package of tiny pieces, perhaps you can see that the difference between kale and pale is assuredly not a single perceptual unit, but a jumble of bits which-- to those who have learned how to organize them-- can be packaged as either "k" or "p", respectively. Maybe it's easier to understand, now, how the characteristic bits of a phoneme can be very particularly recognized and distinguished from another but still be comprehended only as part of a word. Maybe it's easier to see why phonemes are learned from being repeatedly heard in streams of language rather than by comparing them to each other; their bits have to be heard together so they can be associated together. Without any awareness of how to mentally organize auditory bits into a "phoneme", otherwise-phonemic characteristics must be intractably and inextricably assigned to a word-object instead.
Or, rather, to a syllable. The syllable does seem to be the smallest natural perceptual unit of language. Although it's been shown that prelinguistic babies can segment syllable pairs from a speech stream, Nazzi et al (2006) show that French babies, whose native language stresses all syllables equally by default, are perfectly content to stick with syllables instead of sticking syllables together. But why would anyone group a whole syllable together, when even a phoneme is a cluster of multiple acoustic bits?
Bregman, although not intentionally writing about syllables, offers an explanation: "...units are formed whenever a region of sound has uniform properties and boundaries are formed whenever properties change quickly." (p 72) For the most part, this must be true. Syllables tend to begin with an abrupt rise in intensity. You can read most of the words in the sentences I'm writing and, if you speak the syllables slowly, you'll realize that each syllable does have a definite acoustic attack, continuation, and cessation. It is mostly reasonable to say that a rapid rise or drop in intensity signals a syllabic boundary, whether caused by a consonant's plosive or stop, or by the swell of a fresh vowel. Here's a little more perspective from Bregman (p 66):
This suggests that in at least some cases, the auditory system is focusing on the onset of events. This is very sensible of it. It is at the onsets of sounds that things are happening. It is the onset of the piano tone that tells you when the pianist's finger hit the key. The tone's duration tells you about the resonance characteristics of the piano but not about when anything has happened... When the auditory system places a sequence of such short percussive sounds into the same stream, it is not treating them as parts of a single environmental event, but as a series of distinct short events that have all arisen from a common source. By measuring their onset-to-onset times, it is determining whether they are close enough in time to be grouped.
He's right to say "in at least some cases", because onsets do not explain every boundary. After all, the onset of each syllable in the word "sentences" is clear enough, but in the phrase "plosive or stop", why wouldn't we hear "plo-si-vor stop?" Curiously, if I'm understanding Grosjean (1987) correctly-- we do. Apparently, the phrase is initially perceived as "plo-si-vor stop"... but then, after hearing it, our brains re-organize it into "plosive or stop" because we know that "or", not "vor", is a word. Grosjean followed by Cutler et al (1988) have put this idea in my head. We naturally perceive strong syllables as separate, they said, but then dynamically group into those strong syllables the sounds that come after-- and before.
There are precedents for this in both music and language which Bregman does describe (although, again, not directly). For example, a low-intensity note, after being sounded, must reach a certain intensity before it is psychologically considered to have "begun"; similarly, consonants like "b" and "g" have negative onset times because they are typically voiced before being spoken. You can try that now; you may be surprised to hear yourself generating a vocal vibration before saying "buh" or "guh". Although of course it's possible to speak these consonants intelligibly without this initial vibration, the point is that the vibration precedes the consonant's onset. The vibration is psychologically grouped with the point of higher intensity. Also, if a long bowed bass note were interrupted by a trumpet, so that the bass could not be heard over the blast, the return of the bass note-- despite literally "reappearing"-- would not be perceived as a brand new tone but as a continuation of what had come before. (You might note that this is a direct analog for a visual object being occluded by a second object placed in front of it, where the bass note is interrupted in time rather than space.)
In short, and in two: Stress acts as a lexical magnet, and sustained energy maintains continuity.
I'm fascinated by this idea because, as far as I can tell, it's fractal. I can look at language at almost any level-- phonemic, syllabic, phrase, statement, or structure-- and see the same principle operating on the linguistic units at that level. If I'm understanding this principle correctly, it has provided the missing piece which finally allows me to explain how I read.
This afternoon, I took two sentences from a speech I know, from Joseph Heller's Something Happened, and marked them according to the emphases I would instinctively apply to them if I were to speak them aloud. Then I assigned numbers to what I perceived to be the relative levels of stress (1 the loudest, 4 the quietest).

Then I attempted to draw brackets around the phrases, and circles around the sub-phrases, and was surprised that I couldn't do it. The three bracketed phrases were fine (they're each of the three lines above) but the circles only indicated groups. They didn't indicate direction of thought-- which, in turn, surprised me by existing. That is, I hadn't thought about the fact that the words of "very pretty face" individually point forward, but that the entire phrase hearkens back to the beginning. I couldn't draw a circle around all the words from "my" to "face" without visually implying that the circle exists prior to speaking the word "face" (which it certainly doesn't). As I suppose I might have predicted, I soon realized that the stress numbers I'd written were the key to the mess. You can listen to how it sounds and feel how the sense of the speech evolves through the major stresses drawing the minor stresses into themselves. In the first bracket (line), "but doesn't believe it" clearly belongs to "my daughter"; the entire second line is backwards, drawn forward to the final word; the third line demonstrates a shifting hierarchy, where the most critical word is behind, then ahead, then behind again. I notice too that I use tempo as a grouping cue for the unstressed and less-stressed syllables.
Now let's see if I can read the sentence with equal stress on everything. Yes... there. This is simply a result of my reading the sentences syllable-by-syllable, not attending to structure or meaning at all. The artifacts that emerged-- monotone, hyperarticulations, running out of breath-- occurred as a natural consequence, and this is why most people don't like to "cold read" at auditions. While you're still encoding sounds, you're stuck with this most basic level of interpretation: what it says, not what it means.
In the first of these two recordings, you may have noticed that I didn't actually return to my natural tonic until I'd reached the end of the second sentence. This was not a conscious musical choice, but reflects the fact that I maintained an active physical energy throughout. When I was reading Eureka, I discovered that this applies to longer, more complex ideas as well. I began recording one day when I was awfully tired, and I felt the unusual sensation of collapse and disconnect between each paragraph. Each new paragraph was totally new, detached from the main narrative, starting from a cognitive zero point, and immediately became confusing and uninteresting. (I threw out the session.) Nobody can remain away from their tonic for five hours straight, of course; energy is maintained by not breaking the connection to the audience. Staying above your tonic indicates I'm not done yet; presenting your tonic to an audience asks Shall I go on?-- but only if you actively wait for an answer.
I have no doubt that many, many studies have been conducted on the hierarchical structures of language. What I find fascinating, today, is the apparent fact that these structures rely completely on basic metrical information-- stress and tempo. I've said, alternately, that I read holistically and that I read down to the phoneme; that I'm both completely oblivious to and totally aware of the phoneme. Now I have the explanation. When I look at a page of normally-composed text, I infer its structure; what this means is that I instinctively know the spatial position of the words which will receive stress, and what level of stress they should each receive. Equally essential, I know which words are unimportant and should not be stressed. When I reach one of the stress words, I apprehend its syllables and phonemic structure well enough in that instant that I can activate or energize any of them as I wish (as are best appropriate).
The reason I'm going on about this is that today, for the first time, I actually heard two musicians doing this on their instruments. It was delightful to listen to and interact with musicians who were undeniably world-class masters of their craft, and in listening-- no, feeling their work, to know for certain that I'm not merely speculating about a parallel between their music and my language. It is the same. What struck me most fully was that, as this was not merely a concert, the pianist explained her philosophy of art and the nature of the particular composition they were about to perform, and she provided a demonstration on her instrument which was essentially identical to the two sentences I've used here. She first played the piece exactly according to the regular meter as notated, and it was dull as dishwater. Monotonous, homogeneous, meaningless. Then she played the same segment again to illustrate what it Really Meant... and what changed? Stress levels and tempo. In a word, phrasing; but it was abundantly clear from her demonstration that phrasing, and consequently meaning, is accomplished by using stress and tempo to induce segmentation and grouping in a listener's mind. The meter of a musical piece is no more a slave to the metronome than Shakespeare is a slave to the duple beat; meter (in music or poetry) is indicative of how a work is structured, not how it must be produced.
And there's one more step to take: movement. It all comes back to movement, and if you think of a purposeful movement you'll easily see how it should happen that we would want to group information about the strongest movement. Imagine something as simple as taking a sip of coffee. There are a host of movements inherent in this act-- shifting one's body to reach, uplifting the arm, manipulating the hand and fingers to the cup, and so on-- and yet all of these motions are recognized as centrally organized to the single purpose, the single "strong syllable" of taking a sip. Here I equate purpose with strength, and even though "sipping" might not seem a muscularly strong action compared to, say, lifting a barbell, taking a sip is in this case the most meaningful component of the entire system of motion. It is the action to which all the rest is in service. If it helps, you can imagine the system of minor actions which are attendant to some literally "strong" action, like lifting a desk or chopping a tree stump, but note that in these examples too it is the purpose to which the strength is given.
I contend that music is a language that objectively expresses emotion.
Music is a language. I would disagree that music is like a language. The arguments of those who claim that music is like a language, but is not language, seem to hinge on the notion that "language" must express word-based ideas. Musical language expresses musical ideas; music is the only way to express musical ideas directly and unambiguously. Verbal language expresses linguistic ideas; dance expresses movement ideas; music expresses emotional ideas. The fact that we incorporate "prosody" and "gesture" when we speak should not confuse anyone into thinking that these two aspects are integrally part of verbal language; they are separate modes of expression in their own right.
Music is objective and deliberate. I would disagree that music is subjective and abstract. It is true that when a person attempts to use language to describe music, their descriptions must be subjective and often abstract, but the music itself is neither. Ultimately, a literal understanding of music must not be of its ability to make its listener feel an emotion, any more than a literal analysis of language does not account directly for whether a listener understands or agrees. Music shall be understood as the literal representation of a particular emotional experience.
The foundation of expression is timbre and tonality as body shape and body state. By virtue of its shape, any person's body produces a unique and particular timbre; at rest, their body also produces a characteristic tonality, with a specific and unwavering musical tonic. When the entire body is agitated, or the entire body is hyporelaxed (such as in depression), that uncharacteristic level of tension is directly represented by a change in tonality; tonality thereby communicates a speaker's relative state of tension, thus establishing his current mood. (For simplicity, I will refer solely to "tension", assuming that relaxation is an absence of tension.) This may be why a piano, despite its being capable of producing any of a myriad of tonalities over practically the entire range of musical sound, is stereotypically imagined to play in C-major and most characteristically within the "middle octave" besides; in any case, no one could refute that there are certain ranges which are more appropriate to certain instruments. The same pitch range that sounds normal and stable on Instrument One can feel abnormal or comical on Instrument Two.
Multiple instruments, playing simultaneously, represent varied parts of a single complex body. A symphony is not an aggregation of individuals each competing separately to have its say (in its "line"). Any single musical instrument is a prisoner of its shape, and can only produce sounds which represent its invariant figure. A musical work will feature multiple instruments to describe, jointly, a more intricate and complex single body of various distinct parts, each of which resonate and respond in harmony with the others, each producing a further aspect of the single musical message-- each providing an additional layer which other instruments cannot naturally express.
A body "speaks" by moving, which creates vibration in the form of "tones". Tones express tension relative to a tonality, or body-state; in the absence of an established tonality, tones are perceived relative to the character of the instrument. That is, any single tone expresses an instantaneous moment of tension relative to the shape and state of the body which produced it. You can feel this for yourself if you tense or relax all your body's muscles as you release a singing tone; your "tonic" pitch will automatically rise or fall as a direct reflection of your current state. Your speaking voice flows around whatever your current tonic-state happens to be; for example, if you simply say "I know!" in an exasperated way you will hear a rise in pitch that is relative to your current state, but which does not agitate your body into a new overall level of tension. A series of tones expresses a series of instantaneous relative tensions which over time, in their collective contour, express a particular emotional message relative to an instrumental body.
An instrument cannot change its body. From your own body, release a sung "tonic", and note the pitch; now tense or relax your body but then deliberately sing the same pitch. Notice that it sounds different. If you want you can even tense or relax parts of your body and hear how your tone again changes, if subtly, with every muscular change. What you hear is a consequence of the fact that you aren't just singing "a pitch" but a complex tone full of overtones; when your muscles change, different overtones are automatically enhanced or inhibited. For any given pitch, the human voice can produce a multitude of tones. It is possible to say the words "let's go!" with either anger, impatience, or excitement, without changing the words' rhythm and without changing the musical pitches at which you speak each syllable. (It's not easy to do on purpose, because your body will instinctively try to change the rhythm and pitch to better change the emotion, but it is possible.) What your body is physically changing-- what creates the audible difference between one emotion and another-- are the resonances and musical structures surrounding each primary, fundamental pitch. A musical instrument cannot do this.
This is, therefore, how I would explain chords and intervals. Because a musical instrument cannot change its body, it always produces the same resonances. Despite variations in intensity, changes in tempo, or tricks of skilled technique, any one tone produced by a specific instrument must always sound exactly the same. By itself, a piano's tritone will always sound like a piano's tritone, always communicating the same emotional feeling. It has to. You cannot change the shape of the instrument and alter its overtone structure. So how can you change the resonances and musical structures surrounding a primary, fundamental pitch without actually changing the pitch?
Answer: add more tones. A single tritone communicates one emotional concept; a tritone combined with a fifth communicates a different concept; a tritone, fifth, and tonic together express something different still. This is not merely additive; a combined musical sound is not perceived as a collection of its parts. When you hear a major chord you hear a major chord, regardless of any awareness you might have of its intervals or pitches. Our conscious experience suggests this to be true; the principle of exclusive allocation demands it. Multiple simultaneous pitches express a precise and specific emotional complexity. Your body ordinarily accomplishes tremendous complexity within any single tone-- and does so naturally, with extraordinary precision-- from the moment-to-moment synthesis of its infinite permutations of thousands of independent muscular tensions. A musical instrument typically cannot achieve musical complexity by manipulating its body around any single tone; instead it must create complexity by manipulating multiple tones within its single body. (This perspective might offer suggestions for considering "atonal" works.)
A necessary implication of this understanding of music is that every one of us, through ordinary linguistic prosody, is already an expert musician. Not only are we constantly improvising new musical ideas in our every utterance, but we are also shrewd listeners. The other day I remembered Fletcher's "Composition of a 13-Year-Old Boy":
The composition represents the thought of a 13-year old boy after studying a picture called "The Last Outpost," in which an Indian who has been driven from the ancestral hunting-ground of his tribe contemplates the waters of the Pacific with the thought that if he is again forced by the white man to move, it can only be into the ocean.
When you listen to the composition, imagine what you hear to be the Indian actually speaking to you. Don't imagine what he is saying-- you probably wouldn't know his language anyway-- but imagine this to be how he is saying it and notice what feeling he is communicating to you. How must he be physically standing or moving to be producing these sounds? How does the music express to you the state his body is in, moment to moment? I'm intrigued by the fact that the composer wrote the emotive words directly on the composition; they're redundant to the music, of course, but that's precisely how you can be sure that you're not making some "abstract" judgment of the piece. You know what it's telling you. (Personally, I am most intrigued by the obvious strength and pride intermingled with the hopelessness and despair-- the image of the broken warrior.) Admittedly, this composition was designed and intended to be a literal expression of emotion, so in that sense it is purposefully easy to interpret what you hear; and yet I take encouragement in this to recognize that any of us are capable of conceiving a musical idea, despite having no explicit training to do so.
Before proposing how music is learned, I must explain that "learning music" means becoming fluent in the language. A person who has learned musical language is, most simply, a person who can receive and produce musical ideas, whether notated as dots on paper or vibrating as sounds in the air. Creating variations or musical "improvisation" becomes as natural as speaking, because they are able to conceive the ideas which give rise to the musical sounds. A person who has not learned musical language is one who is capable of reproducing, with or without technical proficiency, only the exact sounds provided to them by a composer.
What function does absolute pitch provide? Never mind for the moment whether absolute pitch is an "ability" or an "inability"; never mind trying to justify the "value" of absolute pitch. What does absolute pitch offer that nothing else can?
Key signature.
Absolute pitch is sensitivity to absolute tonality. That's all it could be. If someone is trained well in "movable-do", they will be able to instantly name any note they hear-- if they know the key signature. They will be able to read or write complicated pieces thoroughly and fluently-- having been given a starting tonic or having chosen a random key. Undeniably, a "relative" musician can, theoretically and practically, accomplish any musical task as skillfully as an "absolute" musician, with one sole distinction: ignorance of key signature.
What, therefore, is lost by an insensitivity to absolute pitch? If music is a language, and my explanation of its nature and biological purpose is reasonable, then lack of absolute pitch ability means ignorance of body-state. Lack of absolute awareness would therefore mean not knowing the relationship of a body to the emotions it produces. For a non-orchestral example, remember the two videos of the New York senator. It's difficult to perform a frequency analysis because spoken voice is full of glides, but it seems in the first video he begins with a tonic of approximately C#3 ("best they've got"), and phrases his first complaints by ending each at approximately D3 and E3, which are minor seconds and thirds. These intervals, at once dissonant and strong, by themselves alone communicate an emotional message of emphatic outrage; from these intervals and nothing more, you may receive an impression that a speaker is emphatically outraged about what he is saying. But nothing inherent in those intervals reveals the fact that the speaker himself is in a state of high agitation. His body's state of agitation is conveyed in its underlying effect on every one of the tones he produces.
From this it would appear that in human voice, tonality and timbre-- body state and body shape-- are essentially the same message. That is, you can recognize human "tonality" without having musical absolute pitch because we human beings change our physical state by changing our musical shape. With every emotional change our body enacts a different physical configuration of tensions and relaxations, which all combine to produce a particular timbre. An instrument cannot change its shape, and thus always produces the same timbre; therefore, different baseline levels of tension are created mainly by selecting different tonal centers. As listeners, we unconsciously perceive the tonal center, but it seems that we perceive the emotive character of the instrument to be its body shape (timbre) with little awareness of its absolute state (tonality). We may be able to perceive that tones are "high" or "low" relative to an instrument's typical range, but if octaves are equivalent this height perception tells us nothing about the relationship between the tonality and that instrument's timbre.
If the analogy is appropriate-- and that's a critical "if"-- then you can consider for yourself the "value" of absolute pitch in music. What is the "value" of knowing how a body feels, separate from and in addition to its explicit emotional statements? I won't speculate about it right now, as you can come up with your own answers; I do think this could explain a number of abilities known to be correlated with absolute pitch, but for now it's enough for me to assert that absolute pitch is an awareness of tonality, not an ability to identify and name individual pitches. The only speculation I'll put forth for the moment is the possibility that each absolute pitch, when recognized cognitively as a single tone, may be an idealized (or crystallized, or reduced) conceptualization of its respective tonality.
How, then, is musical language learned? If musical language is learned in the same manner as spoken language, then it is learned by communicating and decoding. "Communicating and decoding" is different from "listening and repeating". The purpose of communication is to transmit an idea, for which any specific sounds may be appropriate, but are essentially arbitrary; the goal of repetition is to mimic accurately, for which precise replication of sounds is required without regard for intention or idea. The goal of learning language is to learn to communicate; in learning language, "sounding good" or "getting it right" is a secondary artistic function which, when best accomplished, serves and augments communication anyway.
I doubt there is a "critical period" for learning language. The critical-period hypothesis suggests that children are generally "better" at learning languages; that their minds are "privileged" for learning at a particular age. I'm skeptical of this hypothesis because, despite the undeniable fact that children undergo rapid and drastic developmental changes at certain early ages, I know anecdotally that when an adult attempts to learn a language by undergoing the same process as a child must (i.e. "immersion"), with the same relentless exposure to the language and a dogged commitment to successfully communicate, learning the language is natural and easy. Every further difficulty that I'm aware adults may have-- such as dialect-- is most likely the result of some habit which could be retrained if it weren't dismissed as a learning deficiency. To that extent, children might find it "easier" to learn languages if only because they have not yet learned any physical habits and intellectual prejudices which would prevent them from learning naturally, but it's neither easy nor automatic. The picture developing before me of how human beings naturally decipher language would not seem to favor children for any reason other than adults having been trained to be bad learners.
No language is initially heard as anything more than an unbroken stream of incomprehensible noise. With continued exposure and persistent attention, however, a language stream is recognized to be inconstant and irregular; that is, as a series of discrete auditory events with detectable onsets and offsets. A listener begins to notice that some of these little bounded packages of sound (or "syllables") repeat themselves, and due to their repeated recurrence in the ongoing stream these syllables are recognized, extracted, and used as legitimate units. Notice that I don't say memorized. From the studies I've been reading, it seems that memorization does occur when there are no more than a bare handful of units to be learned; but when there are more units than memory can handle (as there are thousands of possible syllables) then it seems more appropriate to state that Step One would be discovering how to detect the syllabic unit. Using this skill, any syllable can be detected and extracted.
Once syllables can be recognized, comprehension expands in ever-widening patterns. Through an unconscious statistical analysis, we detect which syllables appear next to each other most frequently, and furthermore infer the patterns of these repetitions to make informed guesses about how to group unfamiliar sequences into words. As we begin to understand words we become able to speak sentences; as we understand sentences we become able to speak "paragraphs", and so on into continually larger structures.
Notice that this is a process of extraction. This is decoding, not encoding; detecting functional purpose, not assembling unrelated pieces. The process is that of identifying the most essential parts of an entire picture, in their proper relations, so that an idea may be fully comprehended from incomplete information. If we do happen to learn and memorize independent words-- such as a "vocabulary list", perhaps-- the value of doing so is not so we can use these words to "build" sentences, but so we can start to detect those words in sentences spoken to us. The learning material must be completely expressed thoughts to be decoded, not scattered fragments to be memorized. Until a word can be comprehended by its place in a language stream, it might as well not exist.
It is, after all, only the code that's incomplete. The concepts to be spoken are intact from the start. Initial language experience for either adults or children is characterized by the incomplete expression of complete thoughts; but these are neither random sounds nor attempts to "build" grammatical sentences. A child learning English says "up!" because he doesn't yet know "pick me up"; a Russian adult landing at a North American airport may request "ticket, train, please" instead of "I'd like one all-day ticket for the train, if you please." The most critical-- most meaningful-- units and patterns are learned first, which enable the essence of each new idea to be communicated; increasing knowledge of the code allows more elaborate and detailed expression of the same ideas that had fully existed before. It's probably true that a virtuous cycle may develop in which linguistic experience leads to increasingly complex and abstract ideas, but in any case, continued exposure to others' complete and accurate use of linguistic structures allows us to learn the bits we're leaving out, and so begin to include them to be more effectively and thoroughly understood.
Natural language learning, therefore, drills down to the syllable-- and no further. Syllables are the "basic unit". To a person who is only listening or speaking, the available clues and cues for segmenting a stream lie in onsets and offsets, which define nothing smaller than syllables. Delving further, into individual components, requires training or practice deliberately undertaken for the explicit purpose of learning those components.
There are people who hear individual tones without having been trained to do so. They are the exception, not the rule, and from the available literature it seems possible that there is something different about these people's brains-- something similar to, if not directly linked to, autism. A distinguishing feature of autism is an inability to ignore details and characteristics, and the known consequences of autistic perception could lead to the difficulties described by absolute musicians. However, whether or not autism is itself responsible for any spontaneous occurrences of absolute pitch, the existence of autism demonstrates that it is possible for someone's brain to be different from normal in just such a way to potentially cause absolute pitch ability. I have no interest in pursuing this connection. If there is a brain abnormality which can cause absolute pitch, then the ability could only be bestowed through genetic manipulation, which is ethically questionable if medically possible and in any case a dead end for those of us who have already been born. In either case it is not necessary to require an abnormal brain, because absolute pitch acquisition can be explained by natural processes of acquiring phonemic awareness.
The purpose of learning letters is to decode syllables. Decoding syllables is not the same process as hearing or extracting phonemes. Phonemes are not extracted; they are decoded from syllables. Syllables can be extracted from a language stream, but syllables can be reliably perceived within a stream. The same phoneme can sound completely different depending on its co-articulation with other phonemes. The same words can contain completely different phonemes depending on a speaker's dialect. Letters are not learned so they can be extracted from a stream. Letters are learned so that we know what our decoding options are.
The method of learning letters is to decode, decode, decode. We do not learn letters by comparing them to each other; understanding the difference between dog and bog is a consequence, not a cause, of knowing the letters. Remembering the name of a letter (such as "kay") will not enable us to recognize its associated phoneme wherever spoken, but will provide a concept that enables us to perceive the sameness of kale, kite, and kudzu, and to spell these words correctly. It is the process of reading and writing these and thousands of other words which teaches us the letters of our alphabet.
It might be possible to learn letters without reading and writing. Maybe the letter-sounds could be memorized, one by one, without introducing the printed alphabet and the graphemes for each letter. Maybe it could be done-- but has it ever been? And why would it be? I can't think of a reason. And yet musical "ear training" is often attempted without any kind of graphemes; sound-concepts are given letter-names or word-names and those are expected to suffice. I think it's reasonable to suggest that the notion of "ear training" could be done away with in favor of the more encompassing "music literacy".
If letters are learned by decoding, the most helpful reading materials will be any text you already know. If you already know what a text means, then the active process of decoding it confirms that the letters you're reading represent the sounds you're expecting. If you do not know what the text means, then you have to encode it sound by sound, only after which you can reflect on its meaning and try to figure out whether you've encoded it correctly. It's a common habit among would-be educators to respond to "what's this word?" with "sound it out," but this response encourages encoding; it is more helpful to provide the word and thus allow it to be accurately decoded. It is of course ridiculous to expect that the majority of material a beginning reader encounters will already be familiar to him; but recognizing the importance of familiarity helps to understand why "read-along" to spoken word is crucial, and further emphasizes that the value of re-reading a story is not in its memorization but because each time through provides confirmation and reinforcement of decoding its words.
If reading is learned by decoding, then a person will continue to improve with practice, as their comprehension grows in "chunks". Once a reader trusts his ability to apprehend syllables and words, he begins to experience grammar; being comfortable with grammar, he begins to recognize how sentences are arranged; then he begins to comprehend how paragraphs are organized; soon it becomes possible to see paragraphs' relation to a broader argument. That is, a person who reads by decoding learns to apprehend and process the functional structure of what's on the page. For this reason, I can also emphasize that learning to read and write is best accomplished by exposure to good writing; exposure to poor writing only "teaches what not to do" when a person already has enough reading experience that the example of poor writing is an obvious deviation from what has become familiar.
If reading is learned by encoding there is little room for improvement. Because the task is implicitly understood to be generating sound rather than inferring meaning, a reader is forever limited to the quantity of sound that can be captured and encoded in a single glance. The "good" readers learn to grab complete sentences at a look; the "bad" readers slog from phoneme to phoneme; but in either case, the purpose and function of the words and sentences remain a mystery until they have been encoded, comprehended, and synthesized. Reading by encoding, with its multiple steps of laborious processing, is considerably more effort than reading by decoding.
I might even go so far as to say that reading by decoding is a more natural process. We generally comprehend objects holistically and only after recognition, only if it becomes necessary, do we bother noticing their attributes; the only time we attempt to understand objects by "piecing together" their attributes are when those attributes are fragmented or obscured to begin with, making holistic recognition impossible. Reading can be accomplished the same way, where an entire page of text is the object perceived. This is, after all, how we normally communicate.
We speak or write because we have an idea to express, and we express an idea by decoding it into language. In my acting instruction I often describe an idea as a metaphorical ball inside your head, off of which you keep peeling sentences and words until it is exhausted. When recently reading from Something Happened I was surprised to realize that the same thing happens in reverse when we receive an idea; we keep gathering sentences and words, not in linear order, until we have formed a new idea-ball in our own head.
Reading by encoding restricts thinking to an unnatural linearity. Each new sentence is, literally, a new sentence, which must be understood before it can be related to other sentences surrounding it. If what I have seen from my acting students is indicative, then the joining together of these linear statements is not automatic. Once encoded, sentences must be reviewed and consciously analyzed before they can make sense as a cohesive single idea-- and even then it's often difficult, in performance, to conceive the original holistic idea and speak entire groups of statements with non-linear unity.
Writing by encoding may confine our thoughts to the same unnatural linearity. Regardless of the sophistication and complexity of his complete idea, an encoder may be capable of verbally considering only one statement at a time. This may not seem much of a liability in writing stories or informal reactions, which are inherently linear and moment-to-moment, but for expressing abstract and critical thought it could be disastrous. If an encoder has not learned to "think structurally", they may have a complete argument but not be able to "see" it all at once. If this is true, this might explain how some musicians have recently described their experience of composing to me; whatever the ultimate quality of their composition, they feel that they must write immediately, as the notes are passing through their minds, or the work will be lost and forgotten.
This suggests that our ability to comprehend our own ideas is limited by our ability to express them. If there is some grand idea-ball in our head and we can "see" the entire thing at once, we may "check in" with the idea as we are expressing it until the physical image of our expression matches the mental image in our mind. If, however, we can only encode and contemplate one facet of the idea at a time-- through a shifting, sliding window-- it may be difficult to extract, decode, and jigsaw-fit all the facets into their ideal form. I know that when I'm wrestling with an unusually complicated idea it helps to write what I'm thinking (which is why this website exists); by compiling the idea-bits into a form where I can consider them all at once, I can more clearly see the complete idea.
All this together would compellingly suggest an approach to learning music. A student (child or adult) would be exposed to musical streams with the encouragement to hear how they are decoded. Chords would be obligingly provided to assist in the decoding. Once a number of chords had been learned, then the student would be encouraged to decode new streams into chords, and old chords into new pitches, and everything to this point is provided as read-along and sing-along rather than guesswork and rote memorization. As a student's reading skill and facility grows, he may begin to decode his own musical ideas into chords and pitches, and with reading and writing everything spirals into a wonderful virtuous cycle that leads to complete music literacy... all this could work, except that there are still some deep questions that need to be answered.
Big Question: is the linguistic parallel accurate? I have asserted and practically assumed that chords will behave like syllables and pitches will behave like phonemes, and that we can learn these components and their musical structures in substantially the same way that we learn any language and its alphabet. I would expect that you could re-read everything I've written here and seamlessly replace "phoneme" with "pitch", "syllable" with "chord", and "language" with "music". If this is not true then my entire house of cards will fold-- perhaps completely.
Bigger Question: what is the "meaning" of each musical unit? I feel as though, with examples such as The Last Outpost, I've directly and adequately answered, without resorting to linguistic parallel, what a musical "idea-ball" is. But the research shows that, in language, syllables and syllabic patterns are found and extracted as candidates for potential words, that is, the sounds are "mapped" to meanings. It's not difficult to see that first words are stereotypically concrete nouns and verbs: doggie, chair, throw. The concepts they represent are specific, unambiguous, and most often tangible. What are baby's first musical words? Pitches as letters I'm not so worried about; they don't mean anything, so we can give each of them a name and a grapheme and they'll do their job. But if the difference between a "meaningful" and a "meaningless" syllable is literal, in that bat is mapped to a meaning and dak has no meaning, how can one tell the difference between a meaningful and a meaningless chord? To what kind of meaning could a chord be mapped? It seems unlikely that a chord could be given a truly meaningful name, any more than the syllable dak would gain meaning by naming it "plort". Perhaps it would help to associate a chord with a real-life object, but a real-life object is not a musical concept. A musical concept is an emotion-- and even if a chord objectively represents an emotion relative to a human body, how do you map an indescribable meaning directly to an intangible sound?
These are the questions I believe I will be attempting to answer in my research, here at the school in my course of study, and what I've written today are the premises on which my work is currently based.
Absolute pitch may be the ability to identify tonality-- but anyone can locate the tonal center of a musical piece.
"Non-musical" listeners are strikingly competent when they're not being asked to abstract their knowledge into the language of music theory. For example, I just played these note groups for my wife, who has no musical training, and asked her "Which of these feels like the ending of a song?" She replied "Number four... but number three sounds like it belongs together." It's not a coincidence that she picked out the tonic and dominant, respectively.
Doesn't absolute pitch skill therefore rely on note naming? If anyone can pick out a tonic, doesn't that just mean that absolute listeners can identify the note they've picked? But no; I don't think absolute listeners are picking a note to name. In any tonal composition, every sound has an overt relationship to its tonic. Each tone points directly and unambiguously to an absolute tonal center. The tonal center of any musical composition is therefore naturally, necessarily, definitively, absolute; once it is detected, no additional process should be necessary. Any musician could undoubtedly listen to a tonal composition and subsequently sing, whistle, or play the correct tonic-- but a non-absolute musician requires a second step to consider, evaluate, and identify the tonic-pitch they've produced. An absolute musician already knows.
Why the difference? I think the explanation may be inferred from the "semitone error", which everyone seems to use as a measure of accuracy. Terhardt's participants (1982, 1983) were given sheet music and asked "Is this recording in the same key, in a higher key, or in a lower key?" and Terhardt excitedly highlights the fact that 45% of participants are accurate "within 1 semitone." Eleven years later, Daniel Levitin (1994) recognized that musicians and non-musicians alike could sing their favorite songs accurately "within 1 semitone." Consistent semitone errors are often taken as a sign of absolute pitch ability, but I have to disagree.
Semitone errors don't make sense. If a piece of tonal music directs and channels you, unambiguously, to its absolute tonal center, how could anyone be "off" by a single semitone? A single semitone "down" is a major seventh; a single semitone "up" is a minor second. While the music is playing, neither of these scale degrees would be mistaken for a tonic, even by the most naive listener. The only way a semitone error could occur, therefore, would be if the listener's judgment were made independently-- despite the music being listened to, not because of it.
How could a semitone error be a correct answer? The most sensible explanation is the one found in Bregman's Auditory Scene Analysis: the assumption that different musical frequencies are distant, not different. If you accept that pitch X is "over here" and pitch Y is "over there", and that this is the only important distinction between the two, a semitone error is a good answer because it's in the right "area." However, this is a judgment based on Tonhöhe (tone height), not Qualität (chroma). For a semitone error to be correct, you have to accept that all pitches are qualitatively identical, so that "pitch" is a measurement along the complete spectrum of vibratory sound frequency. To make an absolute judgment of pitches whose defining quality is height, you cannot and do not have in your mind any concept of unique individual chroma. Instead, you must have an image of the entire undifferentiated spectrum, so that you can fit any pitch into its place on that spectrum.
In true absolute judgment, "within one semitone" is not a near miss. It is a wrong answer. Yes, absolute listeners can make semitone errors, but this is because of notes' similarity of chroma, not proximity in height. To make an absolute judgment, it is necessary to start thinking of pitches as "qualities" of sound, not "areas".
Trying to learn "qualities" of tone chroma, however, is a complete waste of time. Let's say, for example, you learn that an F-sharp is "twangy" and an E-flat is "mellow". To begin with, you can't possibly know what aspect of the tone is giving you that impression-- timbre, dynamic, rhythmic position, scale degree, etc-- and any quality you train yourself to hear will necessarily change (or vanish) when its context changes; but this process is an impossible proposition from the start. Our minds simply don't work that way. Our minds can only assign characteristics to an object after the object itself has been understood, and you can test this for yourself. Pick any object you like, as ordinary and common as you please, and try to describe it to someone else based on some "quality". This thing in front of me, for example: it's white. Not good enough? Um, it's cylindrical. No? All right... it's about five inches long and three inches radially. And... it has a semicircular outcropping. You probably could make a good guess about what this is, but it would still have to be a guess, and it would always be a guess; I could put it right in front of you and you would only be able to say "that's probably it" because it's not the only object that could be described this way. If, however, I told you I have a "coffee mug"-- only then does any single part of the description truly make sense. Describing an object's perceptual characteristics alone can not and will not ever create a shred of comprehension; trying to teach yourself absolute pitch by learning perceptual characteristics must therefore result in failure. It's not the way our minds work.
Any object is understood because of its function. Adults of any age are perfectly capable of learning all kinds of new objects, whether real or abstract, so it would logically follow that to learn an absolute pitch, you must learn its function. What function does an absolute pitch serve? There are certainly thousands of people who will tell you "none at all", but one answer has lately been of interest: an absolute pitch functions as the first tone of a melody.
"Melody triggers" is currently the core strategy of Pitch Paths and Modlobe, and had been the primary thrust of Prolobe (which may some day return). I became curious about it and wrote myself a little widget to try it out. To my surprise, in a very short time, I achieved 70% accuracy across three octaves-- and my reaction times were as fast or faster than the absolute musicians measured by Miyazaki (1988). Although I couldn't be sure how much of my success was due to the melodies' interaction with my own Ear Training Companion software, the results were striking enough that last year, while at Indiana University, I proposed to Rob Goldstone that putting the "melody trigger" system to a scientific test would be an interesting project. He agreed and, with his support, I set to it.
I didn't realize how ambitious a project I had designed until I asked non-musicians to start doing it. Sit for an hour every day, for ten days-- pretest, 8 training sessions, and posttest-- for some irrelevant, difficult, frustrating task? Even with the promise of payment, the drop-out rate was 3 out of every 4. I finally managed to get 18 people to complete it: 5 listened to melodies, 6 sang the melodies out loud, and 7 (the control group) trained with single notes and no melodies.
The results failed to be impressive.
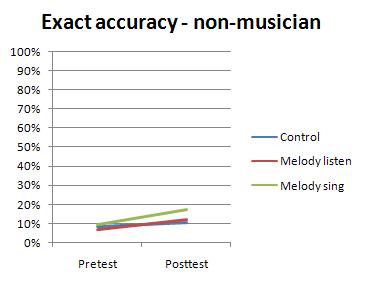
I ran these results through an analysis which told me, rather forcefully, that I could draw only one statistically legitimate conclusion: The melodies did not help. The basic problem wasn't that nobody improved-- it was that everyone improved, with or without melodies. Even with only 18 participants, the statistics told me that all 18 of them, including those who were just trying to memorize single notes, became significantly better at identifying tones. I could see on the graph that melody singers did do the best of all, lagged by melody listeners and finally the no-melody group, so it seemed possible that getting more participants would increase the "power" of the analysis and show the difference between groups to be statistically meaningful after all-- but a statistical difference between the groups wouldn't change the fact that the no-melody group made a significant improvement.
On the one hand, I couldn't be disappointed by this result. I have asserted more than once that people who try to get better at note-naming will get better at it no matter what method they use, and this experiment shows statistically significant gains after only 8 hours' training on nothing more than single tones, without any melodies or tricks or supposedly specialized "perfect pitch training" of any kind. On the other hand, it was baffling; why were the melodies so ineffective? It had to do with musicianship. My own results must have been the consequence of having used the Ear Training Companion (the only ear training I'd ever done); what might happen if musicians tried this same training process?
Musicians were more willing to complete the study, of course, because they thought it was fun and interesting, but it was the summer and I was only able to bring in 8 of them before leaving for Canada. 5 were melody listeners, and 3 were melody singers. There were no single-tone learners, which is unfortunate, because it would've been worth seeing how they improved in comparison.
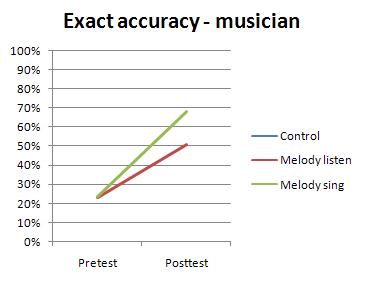
There weren't enough people to do a statistical analysis, but the singers' 44% improvement seemed more impressive to me than the 7% of the non-musicians. I guess the melodies must work, I thought, but only for musicians. And then, because every note-naming study to date has also included the results "plus or minus one semitone", I decided to take a look at that too.
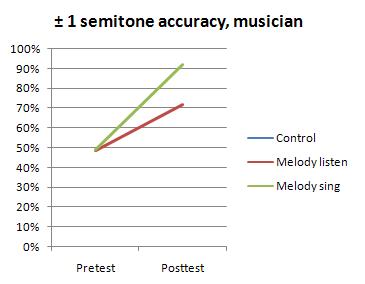
At first glance this seemed even more impressive. 92 percent over three octaves! Not bad! ...but wait. If they got 68% exactly correct, then this means fully 24% of their answers were semitone errors. And... the quantity of semitone errors didn't change at all from pretest to posttest. The percentage increase in accuracy was the same, irrespective of semitone errors.
Or, put another way, no participants became better at identifying tones. All participants became better at locating areas on the overall spectrum. If the participants had become better at identifying tones absolutely, if they had become better at identifying tone chroma, they would have become at least somewhat better able to distinguish each tone from its semitone neighbors. This did not happen. Instead, they became more able to localize pitch height, in the usual resolution of "within one semitone".
Once I realized this I went back to my melody-widget; I certainly had felt that I was identifying the tones, not some area of the total spectrum. I was somewhat dismayed to discover that, after a lapse in training, I was making semitone errors all over the place. Not always, and not consistently, but enough to convince me that I couldn't be certain I wasn't making at least some of my decisions based on height-area instead of chroma-quality.
This experiment is not a complete repudiation of using melodies, but it does cast doubt. Some reports in the forum suggest the possibility that functional comprehension from melodies combined with chroma detection from Absolute Pitch Blaster would produce great results; although that sounds like a good way to circumvent the "area narrowing" I was describing, and make better chroma judgments, I was more concerned about why that should be necessary. If functional comprehension through melody recognition was an absolute judgment, why was it an assessment of height rather than chroma?
Something clicked when Peter wrote to me with enthusiasm for melody triggers. He told me that he can now recognize pitches in his environment that he couldn't before-- by hearing the "trigger" pitch the melody would appear "spontaneously" in his mind. It struck me that this is exactly the kind of experience that I was having which made me feel I was making absolute judgments with my widget, and as I contemplated this effect it dawned on me what the problem was. I considered the process: you hear a pitch and compare it to its melody. If the melody "fits" the pitch, you've correctly identified the pitch. But...
How do you know that the melody is right?
That's the problem. That must be what's going on. Think of the process: hear a note, compare it to a melody. This is a relative judgment of pitch, not an absolute one. The only "absolute" pitch in a melody is its tonal center; all other pitches are functionally meaningful only in their relationship to that tonal center. If you learn a pitch because of its position within a melody you must be learning its scale degree, not its absolute quality. Yes, it would seem that through the use of "melody triggers" a person is learning to identify pitches absolutely, but this process is not an absolute judgment of any pitch. It is an absolute judgment of melody. The apparent ability to identify a pitch is actually the ability to make a relative association with an absolute melody, which Levitin and Terhardt have shown is accurate "within a semitone." In short, "triggering" a melody is not the function served by an absolute pitch.
G, for example, is reliably "the first pitch of Beethoven's Fifth" ...unless Beethoven's Fifth is transposed. Never mind the artistic heresy of transposing Beethoven's Fifth; Beethoven's Fifth transposed will still be completely recognizable. Its first pitch could be anything. The fact that Beethoven's Fifth is ordinarily played in C minor means that if you remember the song in C minor, its first pitch must be G; but only if you remember the song in C minor... in which case the pitch you're remembering is actually C, not G. Finding a G-pitch is merely a side effect.
Unfortunately, this observation creates a Catch-22. You can comprehend an absolute C because it is the tonal center of Beethoven's Fifth, but you can't accurately identify the tonal center of Beethoven's Fifth without comprehending an absolute C. I'm sure that this contradiction must be why judgments of tonal center are usually made by height-area rather than absolute chroma; that is, because absolute C is not comprehended (but tone height is). It's also likely that this may be why people have had success combining Absolute Pitch Blaster with melody triggers, because Absolute Pitch Blaster makes it more possible to comprehend absolute pitch chroma, thereby ameliorating the contradiction.
I don't yet see any way around the contradiction. The principal issue is the identity of transposition; the tonal center of Beethoven's Fifth may be C, but C is not necessarily the tonal center of Beethoven's Fifth. Chords don't seem to offer much better help, because I've realized that my own success at Chordhopper comes at the same price: relating the chords to known melodies. I have noticed that my melody-association for chords is far stronger than for single pitches, presumably because the pitches of each chord interact with each other to provide a more complete feeling of key, but my judgment is still dependent on an accurate memory of the original melodies' absolute pitch center.
Still, I am optimistic. Detecting chroma was originally a Catch-22: you couldn't detect chroma without knowing what it is, but you couldn't learn what it is until you could detect it. That hopeless contradiction turned out to be a direct consequence of the indirect methods people were using (again, the "mellow" and "twangy" thing). I found a way around that with perceptual differentiation, which forces your mind to detect chroma directly despite not knowing what it is. This has proved to be an incomplete solution for the same reasons I described at the beginning of this writing-- because chroma is a characteristic, not a function, even if people hear chroma correctly they fall back on their height-strategy to identify it because that's the only function they understand an isolated pitch to have.
I've realized that the asserted function of melody triggers as "A is for Apple" (or, in my adult experience, "Ö is for Öffnen") is not correct. Although intellectually analogous, it is physically inaccurate. A word is an invariant physical gesture; if the gesture changes, the word changes, and therefore you can be (almost) completely certain you've spoken a letter correctly by starting with it as an individual gestural component and then adding the remaining gesture. If the gesture is accurate, the sound comes out correctly; if you start with the wrong component, the entire gesture must go wrong. If you start with a "wrong" pitch, however, you can still create a perfectly accurate melody. Maybe most of the time you won't, but the mere fact that you can means that "A is for Apple" is not an appropriate comparison.
The question to be answered, then, is this: How can an absolute pitch be described, functionally, so that no other pitch fits the same description?
Anyone who's been paying attention will notice that the time between articles has expanded drastically since my arrival at McMaster University's PhD program-- although I think quality has benefited from the delay (for sifting out casual thoughts), this is only the fifth time I've attempted to write anything since the academic year began. This isn't merely a consequence of my time being demanded by classwork and other projects, although that commitment has not been insignificant; it's because I've come to discover that, astonishingly, it seems I won't be able to study absolute pitch here, not in the way that I expected.
The basic problem is that the premises I've developed in the last few years are in stark opposition to the Generally Accepted Facts about musical perception. Granted, these "facts" are themselves still theoretical, but there is consensus about various assumptions which I cannot accept if I am to proceed; as just a few examples, off the top of my head, here are a few I kept running up against:
- Music is like a language, but is
not actually a language.
- Absolute pitch is the ability to name notes.
- Pitch is the "height" of a tone.
- A musical interval is the "distance" between two notes.
- Absolute pitch is a useless, even harmful, genetic affliction, and is
inherently unmusical.
And, bizarrely, every time-- every time, every single time, without exception-- I mentioned my research interest to anyone who was familiar enough with music that I didn't have to explain what "absolute pitch" meant, I got the same immediate reaction: an astonished, disdainful look coupled with an incredulous "Really? Why?" As you might imagine, then, finding myself blocked or struggling at every turn made it quite difficult to do anything meaningful.
But the problem isn't merely the fact of struggling against the tide. I've never had any problem standing alone to thumb my nose at conventional wisdom (often enough to my own regret). The core issue is that I can't study the theories I've developed and expect to Get Published without first demonstrating, suggestively if not conclusively, the validity of their underlying premises; and just tackling any one of the few I've listed above is the work of years, not something to be casually run through in a few months of graduate study. On the other hand, I could sidestep if I already had some kind of whiz-bang result that would be so potent it would force people to reconsider every one of their prior assumptions-- but even now all I have is anecdotes and possibilities, and the only way to get more will be to proceed as though the premises were solid, which in turn I can't officially do.
Officially, I've changed my course of study to something for which I do have a whiz-bang result-- namely, teaching dialects and accents-- in the hope that it's not too late to have done so. Unofficially, I don't see this as much of a change, because it's still about language production and perception as a function of cognitive and muscular habit, but I don't need to bother them with my understanding of the connections; mainly I need to regain my footing in this musical work and continue forward on my own.
![]()